Questo protocollo fa parte di un insieme di standard internazionali prodotti
per facilitare l'interconnessione di sistemi aperti.
L'IS-IS permette agli Intermediate System (IS) all'interno di un dominio
di Routing di scambiarsi configurazioni e informazioni di Routing per
facilitare le operazioni di instradamento e le relative funzioni dello strato
di rete.
Questo protocollo è stato progettato per lavorare in stretta
congiunzione con due normative ISO la 9542 e la 8473 le quali servono
rispettivamente a stabilire la connessione e la raggiungibilità tra
End System (ES) e Intermediate System (IS) all' interno di
sottoreti individuali, e l'altra serve a regolamentare il trasporto dei dati.
Il protocollo OSI IS-IS Intra Domain è capace di supportare Grandi
domini di routing che come vedremo saranno organizzati gerarchicamente.
I domini consistono in diverse combinazioni di molti tipi di reti, ad
esempio : Point To Point Link, Multipoints Link, reti X.25, reti
Broadcast (Ethernet e FDDI). Un grande dominio sarà diviso
amministrativamente in Aree e ogni (IS) risiederà esattamente
all'interno di un'area ben definita. La divisione gerarchica consta di due
livelli il Livello1 e il Livello2 quando parliamo di routing al
livello1 ci riferiamo all' instradamento (dei pacchetti) all' interno di
un'area mentre routing al livello2 è riferito all'instradamento fra aree
diverse o al di fuori del dominio (il dominio è da considerarsi come un
Autonomous System (AS).
Diamo ora delle definizioni più precise circa gli (IS) di livello 1, gli
(IS) di livello 2, e gli (ES):
· END SYSTEM : questo è un sistema che può
sia spedire che ricevere i pacchetti NPDU
(Network Protocol Data Unit) agli altri sistemi, ma non le può inoltrare
essendo connesso ad un solo (IS).
· INTERMEDIATE SYSTEM LEVEL 1 : questo sistema
può ricevere , spedire ed inoltrare agli altri (IS) le NPDU. In oltre se
la destinazione di una NPDU è nella sua area la instraderà
direttamente, altrimenti la passera' al router di livello2 più vicino.
· INTERMEDIATE SYSTEM LEVEL 2 : questo sistema ha le
stesse caratteristiche di un (IS) di livello1 ma in più ha la
capacità di instradare le NPDU verso destinazioni al di fuori della
propria area e anche del dominio di routing.
Gli (IS) di livello1 e 2 mantengono all'interno dei database diversi gli (IS)
di livello2 manterranno informazioni circa i paths tra aree diverse , mentre
gli (IS) di livelli1 avranno a disposizione nel loro database tutte le
informazioni di routing riguardanti la propria area interna. Ad esempio: se un
pacchetto NPDU è destinato ad una area diversa da quella a cui
appartiene l'(IS) di livello1 da cui stiamo spedendo l' (IS) manderà la
NPDU al più vicino router di livello2 della propria area, a questo punto
la NPDU viaggerà attraverso i livelli2 fino all'area di destinazione
dove andrà di nuovo in un livello1 fino all' (ES) di
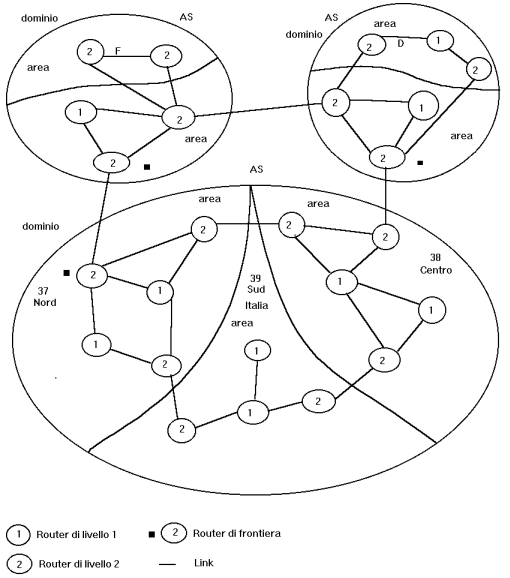
destinazione. Schema generale di un dominio di routing diviso gerarchicamente
e amministrativamente rispettivamente in livelli e aree
Organizzazione dell' IS-IS
L'organizzazione dell' IS-IS è divisa in due tipi di funzioni principali che sono:
SUBNETWORK INDIPENDENT FUNCTIONS : queste sono funzioni indipendenti dal tipo di sottorete che stiamo usando, esse provvedono principalmente a fornire una trasmissione full duplex delle NPDU tra NEIGHBOUR SYSTEM (sistemi vicini) e si dividono a loro volta in :
· ROUTING : il quale determina le paths della NPDU e ne gestisce le caratteristiche dinamicamente , ad esempio se un link va giù il routing provvede a trovare una path alternativa.
· CONGESTION CONTROL : il quale provvede a gestire le risorse utilizzate da ogni (IS).
SUBNETWORK DEPENDENT FUNCTIONS : queste sono le funzioni dipendenti dalla sottorete che stiamo utilizzando e servono principalmente per mascherare le caratteristiche della sottorete, e si occupano in più di :
1. Determinare la Neighbour Network e l'indirizzo SNPA (porta).
2. Inizializzare i Data Link.
3. Frammentazione passo a passo su sottoreti con SNSDU (Subnetwork Service Data Unit) piccola.
4. Cancellare e stabilire dinamicamente i link.
Schema della scissione delle funzioni indipendenti

Il Decision Process
Questo processo è quello che si occupa di calcolare le paths per ogni destinazione nel dominio di routing ed è eseguito separatamente e indipendentemente per il livello1, il livello2, e per ogni metrica supportata dall' (IS).
Esso si basa sull' uso del Link State Database che contiene tutte le ultime informazioni LSP (link state packets) aggiornate dinamicamente provenienti da ogni altro (IS) all' interno dell'area, il link state database viene mantenuto aggiornato dall' Update Process. Tutti i paths del livello 1 sono contenuti nel Forwarding Database Level 1 per calcolare questi paths viene usato il Link State Database Level 1 mentre per calcolare il Forwarding Database Level 2 viene usato il Link State Database Level 2
Vediamo ora gli input e gli output del processo di decisione:
INPUT
· Link State Database: rappresenta l'insieme delle informazioni prese dall'ultima LSP da tutti gli (IS) conosciuti.
· Notifica di un evento: rappresenta un segnale proveniente dall' Update Process che informa il Decision Process che è cambiato un link da qualche parte nel dominio
OUTPUT
· Forwarding Database Level 1: contiene tutti i cammini per una determinata destinazione ne è presente uno per ogni metrica di instradamento supportata.
· Forwarding Database Level 2: contiene tutti i cammini per una determinata destinazione ne è presente uno per ogni metrica di instradamento supportata, le informazioni riguardano solo i router di livello 2.
Metriche Di Routing
Ci sono quattro metriche definite che corrispondono a quattro qualità di servizi (QOS Quality Of Service) vediamo quali sono:
1. Default Metrics : questa metrica è supportata da tutti gli (IS) nel dominio quindi ad ogni circuito sarà assegnato un intero positivo che per convenzione misura la capacità del circuito di maneggiare il traffico (troughput) più alto è il valore più bassa è la capacità.
2. Delay Metrics : questa è una metrica opzionale se gli viene assegnato un valore esso rappresenterà il ritardo di transito associato a tale circuito più è alto il valore più sarà alto il ritardo di attraversamento.
3. Expense metrics : questa è una metrica opzionale se gli viene assegnato un valore esso rappresenterà il costo monetario dell'utilizzo di quel circuito più è alto il valore più sarà alto il costo di attraversamento.
4. Error Metrics : questa è una metrica opzionale se gli viene assegnato un valore esso rappresenterà la possibilità di errori residui su quel circuito più è alto il valore più sarà alta la possibilità di errori non scoperti questo valore se assegnato sarà diverso da zero.
Qualunque (IS) sarà capace di calcolare una path secondo la metrica di default, se un (IS) supporta il calcolo di una path secondo una o più metriche opzionali allora il processo di update riporterà il valore per questa metrica nella LSP associata al circuito altrimenti no.
Broadcast Subnetwork - Pseudonodo
La Broadcast Subnetwork viene trattata come uno Pseudonodo con un link ad ogni punto di attacco vediamo come si costruisce e a che cosa serve uno pseudonodo.
Due (IS) non si considerano neighbours fino a quando ognuno ritiene l'altro direttamente raggiungibile mediante una delle loro SNPA ci sono due casi diversi a seconda della rete utilizzata , in un collegamento Point-To-Point i due (IS) in questione si accerteranno di essere neighbours scambiandosi un pacchetto chiamato HELLO PDU, mentre in una rete broadcast (Ethetnet o FDDI) ci sarà un (IS) designato che provvederà ad accertare l'insieme di (IS) che possono comunicare (Link Up) e li includerà nella LSP che esso genera per rappresentare lo pseudonodo.

(IS) con tutti i link

(IS) rappresentato da uno pseudonodo
Come vediamo in figura ogni router sarà collegato agli altri tramite più link l'(IS) designato terrà conto di tutti i link ma nella sua LSP ne specificherà soltanto uno per ogni router in modo da snellire le informazioni, creare meno traffico ed avere dei database più piccoli.
LSP Multiple
Il processo di update può dividere una singola LSP in LSP separate allo scopo di conservare larghezza di banda, ci sarà una LSP in particolare, la LSP numero 0 che verrà vista dal processo di decisione in modo speciale in quanto contiene delle informazioni che le altre LSP non hanno , in più se all' interno del database non è presente nessuna LSP numero 0 con un lifetime maggiore di zero il processo di decisione non processerà nessuna altra LSP fino a quando non gli viene spedita la nuova LSP numero 0.
Le seguenti informazioni sono contenute solo all' interno della LSP numero 0 :
1. Settaggio del bit INFINITE HIPPITY COST
2. Il valore del campo TYPE OF (IS)
3. L' opzione AREA ADDRESS
Struttura dell' Indirizzo IS-IS

Diamo una breve descrizione dei campi :
il campo IDP (Initial Domain Part) rappresenta il prefisso dell'indirizzo e si divide in AFI e IDI , in AFI c'è il prefisso vero e proprio mentre il campo IDI e' riempito di zeri per rendere il campo IDP di lunghezza standard. Il campo DSP (Domai Specific Part) è suddiviso a sua volta in tre parti che sono :
HO-DSP (High Order Domain Specific Part) dove è contenuto l'indirizzo dall'area in questione, ID (identifier) è l'identificatore della rete a cui si riferisce l'indirizzo, infine il campo SEL (Selector) è un selettore che serve a discriminare tra i diversi tipi di entità a cui può essere indirizzato il pacchetto (Es. entità di trasporto o entità di rete). Come si può vedere in figura i primi due campi sono chiamati area address in quanto rappresentano appunto l'indirizzo dell'area, mentre tutti i campi escluso il campo SEL rappresentano il net address cioè l'indirizzo della rete a cui si riferisce l'indirizzo stesso.
Se un Area Address combacia perfettamente con l'Area Address di un sistema dell'area stessa allora il pacchetto verrà instradato al livello1 altrimenti al livello2 di routing il quale agisce sul prefisso dell'indirizzo e instrada verso il prefisso più lungo dell' indirizzo raggiungibile che corrisponde al Destination Address.
Introduzione all' Algoritmo SPF
L' algoritmo usato dal processo di decisione per il calcolo dei paths è l'algoritmo SPF (Shortest Path First) , il quale gira indipendentemente e concorrentemente in tutti gli (IS) all'interno di un dominio di routing. Il routing all'interno di un dominio viene fatto HOP-BY-HOP cioè l'SPF determina solo il prossimo passo (HOP) ma non il cammino completo che percorrerà il pacchetto (PDU) per raggiungere la sua destinazione finale.
Per garantire la correttezza del calcolo della path da parte di un (IS) ci si basa su uno standard internazionale attenendosi alle seguenti regole :
· Tutti gli (IS) appartenenti al dominio di routing useranno le stesse informazioni a riguardo della topologia del dominio
· Tutti gli (IS) appartenenti al dominio genereranno lo stesso insieme di paths partendo dalla stessa topologia d'ingresso e dallo stesso insieme di metriche.
Un (IS) esegue l' SPF per trovare un insieme di paths per un sistema di destinazione nel dominio questo insieme consiste di :
1. Un unico cammino con costo minimo (Minimum Cost Path)
2. Un insieme di cammini con costo minimo uguale (Equal Minimum Cost Path)
Il processo di decisione nella determinazione del cammino si accerterà anche dell'identità delle adiacenze (ovvero IS raggiungibili direttamente tramite una porta SNPA dall'IS in cui ci troviamo) che trova sul primo HOP verso la destinazione per ogni path. Queste adiacenze vengono usate per formare il Forwarding Database il quale viene usato dal Forwarding Process per inoltrare il pacchetto (PDU).
Notiamo che siccome esistono due livelli differenti e quattro metriche diverse per ciascun livello l' algoritmo SPF verrà eseguito più volte (fino a otto nel caso siano supportate tutte le metriche) da ogni (IS).
Algoritmo SPF (DIJKSTRA)
Questo algoritmo ha una complessità del quadrato del numero dei nodi, è possibile ottimizzare l'SPF se si utilizza un campo a parte per la metrica e usando una struttura dati che mantenga una lista separata dei sistemi per ogni metrica e aggiornandola facendo periodicamente un update completo per evitare la corruzione dei dati.
L' algoritmo SPF utilizza due strutture dati così definite :
1. PATHS : è un grafo di cammini (shortest path) da S che è la sorgente fino a N che è le destinazione, è memorizzato sotto forma di triple < N, d(N), [adj(N)]> dove N è l'identificatore di un sistema (System ID), d(N) è la distanza di N da S (valore totale della metrica da S a N), e [adj(N)] è un insieme di adiacenze valide che S può usare per spedire ad N.
2. TENT : è una lista di triple < N, d(N), [adj(N)]> definite come per PATHS come si può intuire dal nome in TENT ci saranno i vari cammini che si tenterà di mettere in PATHS
L'algoritmo che costruisce i cammini comincia col mettere se stesso in PATHS mentre TENT verrà precaricato col database locale delle adiacenze, dopo questa inizializzazione si procederà provando i vari cammini per una data destinazione, notare che nessun cammino N verrà messo in PATHS fino a quando esiste la possibilità che ce ne sia uno più corto. Quando un cammino N viene messo in PATHS verranno esaminati i cammini per i neighbour M di N . Lo scopo è di trovare la tripla < N, x, [adj(N)]> all'interno di TENT che abbia x minimale.
L'algoritmo SPF termina quando un cammino N viene messo in PATHS e TENT è vuoto questo significherà che non ci sono altre alternative da provare e che il cammino o i cammini attualmente presenti all' interno di PATHS sono quelli di costo minimo, che come abbiamo visto potrebbero essere più di uno.
Può capitare che si sia trovato un numero di cammini superiore al numero massimo consentito dal parametro Maximum Path Split in questo caso l'(IS) discriminerà in base alle caratteristiche che ora vedremo fino a quando non ne rimarranno un numero consentito :
· Adjacancy Type : sono preferiti come adiacenze i prefissi di End System o (IS) di livello2.
· Neighbour ID : dove ci sono due o più adiacenze dello stesso tipo si preferisce quella con neighbour ID più basso.
· Circuit ID : dove ci sono due o più adiacenze dello stesso tipo, e con lo stesso neighbour, ID si preferisce quella con Circuit ID più basso.
Lan Address : dove ci sono due o più adiacenze dello stesso tipo, e con lo stesso neighbour, ID e lo stesso Circuit ID si preferisce quella con Lan Address più basso.
Robustness Check
Quando si interrompe un link all'interno di un'area possono verificarsi tre casi:
1. non e' possibile riparare dinamicamente il link interrotto;
2. è possibile riparare dinamicamente il link interrotto utilizzando i link all'interno della stessa area;
3. e' possibile riparare il link interrotto solo con l'utilizzo del sottodominio di livello 2.
Tratteremo nei particolari quest'ultimo caso.

Schema di un (IS) partizionato
Supponiamo che si interrompa il link che congiunge l'IS (Intermediate System) D all'IS E. È evidente che l'area risulta divisa in due partizioni che indicheremo con Partition1 e Partition2 e che queste ultime possono comunicare solo servendosi del "Link Virtuale" (costruito utilizzando i link del sottodominio di livello due). Quando il link tra D e E si interrompe, ogni IS è a conoscenza di quali sono gli IS che appartengono alla sua stessa partizione (poichè è stato eseguito il processo di decisione di livello 1) .
In ognuna delle partizioni verrà eletto un IS designato. Esso deve possedere le seguenti caratteristiche:
1. deve essere IS di livello 2 con un link attivo al sottodominio di livello 2;
2. deve essere abilitato alla riparazione di un'area (il bit P nella LSP deve essere settato);
3. deve avere l'ID più basso.
Tale IS dovrà quindi comunicare agli IS di livello 2, all'interno della sua stessa partizione, che esso è l'IS designato. A tal fine esso esaminerà tutte le LSPs di livello 2 e cercherà quegli IS la cui AreaAddresses è uguale alla sua PartitionAreaAddresses. Una volta individuati tali IS, essi verranno informati sull'identità dell'IS designato e sul costo del percorso per poterlo raggiungere, ciò sarà fatto tramite il processo di Update di livello 1.
Inoltre, l'IS designato della partizione1 esaminerà le LSPs di livello 2 finchè non trova l'IS designato della partizione2. Fatto ciò l'IS designato della partizione1, tramite il processo di Update di livello 1, propagherà una LSP di livello 1 all'altro IS designato affinchè essi si considerino adiacenti. Proprio tramite questa Adiacenza Virtuale e quindi questo "Link Virtuale" le due partizioni potranno comunicare.
Il processo di Update
Il processo di Update si occupa della generazione e propagazione delle Link State PDU(s) che verranno usate dal processo di decisione per calcolare i cammini.
Generazione di Link State PDUs (LSPs)
Le LSPs sono generate allo scopo di informare tutti gli IS (nell'area, nel caso del livello 1, oppure nel sottodominio di livello 2, nel caso del livello 2), sullo stato dei links tra l'IS che ha generato le PDUs ed i suoi neighbours.
Link State PDU

· LSP ID:

· VARIABLE LENGTH FIELDS:

Se CODE è uguale ad 1 allora il campo VALUE sarà il seguente:

Se CODE è uguale a 2 allora il campo VALUE sarà il seguente:
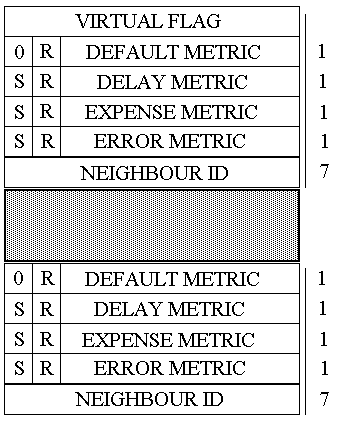
Se CODE è uguale a 3 allora il campo VALUE sarà il seguente:

Una LSP avrà una dimensione limitata, pari al valore fissato dal System Management attraverso la costante "ReceiveLSPBufferSize", per questo motivo potrebbe capitare che un IS non riesca ad includere le informazioni riguardanti tutti i suoi neighbours in una singola LSP. In questo caso, un IS può generare LSP Multiple. Ogni LSP di questo insieme conterrà lo stesso campo SurceID, ma avrà un diverso LSP Number generato sequenziale.
L'IS tratterà l'LSP Number zero in modo speciale. I campi elencati di seguito sono significativi solo se presenti in questa particolare LSP:
1. Infinity Hippity Cost (vedi paragrafo Overload dell'LSP Database).
2. ISType (ci permette di capire se LSP è di livello 1 oppure di livello 2).
3. AreaAddresses (presente solo in questa LSP).
Quando il valore di uno dei tre campi sopra elencati cambia, l'IS rigenera solo LSP Number zero in modo da informare gli altri IS di tale cambiamento. In tal caso le altre LSP Number non verranno rigenerate.
Ogni volta che un IS genera una LSP le assegna un Sequence Number che verrà poi utilizzato per poter confrontare varie versioni di LSPs generate dallo stesso IS (al fine di capire qual è la LSP più nuova).
L'IS rigenera periodicamente ogni LSP ad intervalli di al più "MaximumLSPGenerationInterval" secondi. In genere questa costante viene fissata dal System Management a quindici minuti. Prima della scadenza di questo intervallo si possono verificare degli eventi (es. un adiacenza che da Up diviene Down, un cambiamento nella metrica di un circuito, ecc.) che causano il cambiamento del contenuto delle informazioni e che quindi inducono l'IS a rigenerare una LSP (ovviamente la nuova LSP avrà un nuovo Sequence Number che permetterà agli altri IS di capire che essa è la più recente).
Prima che l'IS possa rigenerare una nuova LSP dovrà trascorrere un intervallo di tempo pari a "MinimumLSPGenerationInterval", esso non dovrà essere nè troppo grande, perchè ciò potrebbe causare un ritardo nella propagazione delle nuove informazioni, nè troppo piccolo perchè ciò potrebbe provocare un overhead. In genere tale costante viene settata dal System Management a trenta secondi.
Infine quando viene generata una LSP, l'IS sorgente calcolerà una Checksum che non potrà essere modificata da nessun altro sistema. Essa permetterà di individuare eventuali errori in modo da prevenire sia l'uso di informazioni di routing incorrette sia la propagazione futura di informazioni scorrette da parte del processo di Update.
Memorizzazione di Link State PDU
L'IS memorizzerà la LSP generata all'interno del Link State Database. Ogni LSP verrà scritta su una LSP, generata dallo stesso sistema e già memorizzata nel database, avente lo stesso LSP Number.
Propagazione di LSPs
Il processo di Update è responsabile della propagazione delle LSP attraverso il dominio (o nel caso del livello 1, attraverso l'area).Prima di addentrarci nei particolari relativi alla fase di propagazione, è opportuno analizzare il significato del flag SRM.
SRM: Send Routing Message (trasmetti messaggi di routing). Quando una LSP ha il flag SRM settato (uguale a TRUE), l'IS è abilitato a propagare tale LSP e dovrà inviare tale LSP a tutti gli IS neighbours eccetto quello dal quale l'ha ricevuta.
Quando un IS riceve una LSP provvede a propagarla al giusto livello (livello1 oppure livello 2).
Non analizzeremo nei particolari come avviene la propagazione ai vari livelli, ma come l'IS gestisce alcune situazioni particolari quì elencate:
a. un IS riceve una LSP con una checksum errata
1. invia un messaggio del tipo "Corrupted LSP received"
2. pone zero nel campo Checksum e Remaining Lifetime e
3. tratta l'LSP come se fosse scaduto il suo rimanente tempo di vita (vedi paragrafo Campo Remaining Lifetime)
b. un Is riceve una LSP nuova
1. memorizza LSP nel Link State Database e
2. setta l'SRM flag in modo che essa venga propagata su tutti i circuiti tranne quello da cui l'ha ricevuta. Quando ha ricevuto l'LSP invia un acknowledgement (ack) (vedi paragrafo Come rendere affidabile l'Update)
c. un IS R riceve da una sorgente S, una LSP che esso considera più vecchia (Sequence Number più piccolo) di quella memorizzata nel suo database per S. L'IS R, allora, setterà il flag SRM in modo che S possa ricevere l'LSP contenente le nuove informazioni ed avente nel campo Sequence Number il valore della Sequence Number di R. Quando S la riceverà cambierà il suo Sequence Number e lo forzerà ad essere maggiore rispetto a quello ricevuto da R, a questo punto S provvederà a propagare questa nuova LSP.
d. un IS riceve una LSP che esso ha già nel suo Database
1. l'accetta se necessario (vedi paragrafo Generazione del Sequence Number e confusione tra le LSPs).
2. cancella l'SRM flag poichè non ha senso inoltrarla.
Il processo di Update scandisce il Link State Database alla ricerca di LSP con il flag SRM settato, quando ne trova una provvede ad inoltrarla.
Campo Remaining Lifetime
Quando un IS genera una LSP esso setta il campo Remaining Lifetime a "MaxAge" (venti minuti). Se le informazioni vengono conservate dall'IS per un certo intervallo di tempo primadi essere trasmesse con successo ad un neighbour, allora il sistema decrementa il campo Remaining Lifetime di tale intervallo di conservazione. Inoltre viene stimato il tempo di transito (in secondi) per poter raggiungere quel neighbour e prima della trasmissione dell'LSP il campo in questione verrà ancora decrementato di tale tempo.
Quando il Remaining Lifetime di una LSP, che si trova in memoria, diviene zero allora l'IS
a. setta tutti gli SRM flag per quella LSP (per avvertire gli altri IS che quelst'ultima è spirata)
b. cancella l'LSP dal Database conservandone solo header
c. dopo circa un minuto (valore contenuto in "ZeroAgeLifeTime") da quando Remaining Lifetime è divenuto zero, l'IS cancella anche l'header
Generazione del Sequence Number e Confusione tra le LSPs
Al Sequence Number e assegnato un valore senza segno costituito da 4 ottetti (32 bit). Esso può essere incrementato da zero fino al valore espresso dalla costante "SequenceModulus". Quando un sistema viene inizializzato esso partirà con un Sequence Number pari a 1.
Se un IS deve incrementare il Sequence Number, ma esso ha già raggiunto il valore "SequenceModulus" l'IS genererà il messaggio "Attempt to Exceed Maximum Sequence Number" e disabiliterà il Modulo di Routing per un periodo pari a MaxAge + ZeroAgeLifeTime in modo da essere sicuro che qualche LSP spiri. Quando l'IS si riabilita ripartirà con un Sequence Number pari ad 1.
Per questo motivo potrebbe accadere che esistano contemporaneamente due LSP con lo stesso Sequence Number creando così una situazione di confusione.
Per risolvere tale problema l'IS quando riceve una LSP avente lo stesso Sequence Number di una memorizzata all'interno del suo database, confronta i valori delle relative checksum. Se tali valori sono diversi e l'LSP ricevuta non fa parte dell'insieme corrente delle LSPs generate dal sistema locale, allora tale sistema memorizza l'LSP ponendo nel campo Remaining Lifetime zero e trattandola come specificato nel paragrafo Campo Remaining Lifetime.
Se l'LSP è nell'insieme corrente delle LSPs generate dal sistema locale, allora l'IS la memorizzerà con un nuovo Sequence Number (più grande di quello posseduto dalla LSP) e la rigenererà.
Come rendere affidabile l'Update
Il processo di Update ha la responsabilità di assicurare che le più recenti LSPs vengano spedite a tutti gli IS raggiungibili nel dominio.
Distinguiamo due casi:
a. link point to point:
Quando un IS riceve una LSP più nuova di quelle memorizzate nel suo database, allora esso invierà un esplicito ack codificato come una Partial Sequence Number PDU (PSNP)
Partial Sequence Number PDU

· VARIABLE LENGTH FIELD:

Oss Nella parte variabile sono contenute alcune informazioni relative alla nuova LSP che l'IS ha ricevuto.
b. Sui link broadcast:
Una speciale PDU conosciuta come Complete Sequence Number PDU (CSNP) sarà periodicamente spedita in multicast (livello 1 o livello 2, ogni dieci secondi) dall'IS designato. Essa conterrà una lista avente solo le informazioni rilevanti per ognuna delle LSP presenti nel Database (vedi figura parte variabile). Potrebbe non bastare una singola CSNP per contenere l'insieme completo delle informazioni, in tal caso, possono essere utilizzate più CSNPs individuali, ognuna delle quali nella parte fissa (vedi figura) porta con sè il range di identificatori di LSP alle quali essa si riferisce.
Complete Sequence Number

· VARIABLE LENGTH FIELD:

Quando un IS riceve una CSNP la confronta con il proprio Database.
Se l'IS si rende conto che alcune informazioni di quelle che gli sono arrivate sono più vecchie di quelle che lui ha nel suo Database, allora provvederà a trasmetterle in multicast.
Se, invece, l'IS si rende conto che alcune LSPs della lista che gli è appena arrivata sono più nuove di quelle presenti nel suo Database, allora trasmetterà in multicast una PSNP contenente tali LSPs. Ciò verrà interpretato dall'IS designato (l'unico abilitato a rispondere) come una implicita richiesta delle versioni complete delle relative LSPs.
Convalida del Database
Un IS non può operare per un periodo troppo lungo servendosi di informazioni di routing corrotte. A tal fine l'IS dovrà operare in modalità Fail-Stop. In tale modalità l'IS effettuerà i seguenti controlli almeno ogni "MaximumLSPGenerationInterval" secondi.
a. L'IS ricontrollerà la checksum di ogni LSP presente nel Link State Database (eccetto quelle con Remaining Lifetime uguale a zero), al fine di verificare se ci sono LSP corrotte. Se è presente qualche LSP di tale tipo, viene generato il messaggio "Corrupted LSP Detected", l'intero Link State Database sarà cancellato e l'IS dovrà ricostruirlo. Un modo per ottenere ciò e quello di disabilitare e successivamente riabilitare l'IS.
b. Successivamente il processo di decisione riceverà le nuove informazioni e ciò porterà all'esecuzione del processo di decisione ed alla ricomputazione del Forwarding Database. In tal modo diviene possibile controllare la correttezza del forwarding Database.
Overload dell'LSP Database
La dimensione di un LSP Database sarà sicuramente limitata. Quindi potrebbe accadere che un IS nel momento in cui riceve una LSP non abbia più risorse di memoria sufficienti per la memorizzazione di quest'ultima, oppure potrebbe accadere che il processo di Decisione richieda delle risorse di memoria che però non sono disponibili.
In questi casi il sistema:
1. si porrà in "Waiting State", per un numero di secondi pari al valore della costante "Waiting Time" (tempo necessario affinchè qualche LSP spiri),
2. genererà e propagherà le proprie LSP Number zero con il bit "Infinity Hippty Cost" settato, ciò al fine di informare gli altri IS che esso è sovraccarico e che quindi non deve essere preso in considerazione per la costruzione dei percorsi di forwarding.
3. in fine quando il "Waiting Time" termina, il sistema genera un messaggio in cui dice che il suo LSP Database è stato recuperato, ed inoltre propaga LSP Number zero con il bit "Infinity Hippity Cost" cancellato, ciò al fine di poter riprendere le sue normali attività.
Sincronizzazione del processo di Update e del processo di Decisione
Poichè il processo di Decisione ed il processo di Update condividono il Link State Database, bisogna prestare attenzione affinchè il processo di Update non modifichi l'LSP Database mentre il processo di Decisione è in esecuzione. Ci sono due modalità operative che permettono di evitare ciò.
Nella prima, il processo di Decisione segnala, al processo di Update, che sta utilizzando il Database. In questo intervallo di tempo il processo di Update mette in coda le LSPs che gli arrivano senza scaricarle nel Database, se però gli arrivano più LSP di quelle che possono essere inserite nella coda, il processo di Update le salta e non invia alcun messaggio per comunicare alla sorgente che esso non le ha ricevute.
La seconda prevede l'utilizzo di due copie del Link State Database, alla prima può avere accesso solo il processo di Update, mentre alla seconda entrambi i processi. In questo modo quando il processo di decisione sta operando, quello di Update può comunque memorizzare, le LSPs che riceve, nella prima copia del Database. Solo quando il processo di Decisione terminerà la sua esecuzione, quello di Update potrà copiare le informazioni del primo Database sul Database che essi hanno in comune.
Il vantaggio del primo approccio è che esso richiede "poca" memoria. Il vantaggio del secondo approccio è che le LSP non vengono saltate.
The Forwarding Process
Il processo di forwarding é responsabile di trasmettere le NPDU originate dal sistema ed inoltrare quelle a lei arrivate.
INPUT:
· NPDU dal processo di ricezione.
· informazioni dal Processo Update.
· e soprattutto il Forwarding Databases (L1 e L2) - uno per ogni metrica ( quindi ne sono 8 ) ma quelle che riceve o sono di Livello 1 oppure di Livello 2.
OUTPUT:
PDU da inoltrare nel prossimo circuito.
La selezione della giusta forwarding dal database é basata su:
- il livello (L1 o L2).
- la metrica.
Il primo é selezionata grazie alla verifica della Destination Address per ogni PDU.Il secondo é selezionato grazie al campo QoS (Quality of Service) presente nella PDU, se non é presente si sceglie sempre la metrica di default.
La procedura principale che chiama la IS é:
PROCEDURE Forward ( level: (L1 o L2); metric: (default,delay,expense,error);
dest: NetworkLayerAddress; Var adj: Pointer to adjacency;
): BOOLEAN;
Questa procedura sceglie da un database di L1 o L2 una adiacenza a cui poter forwardare le NPDUs per quella fissata destinazione. Ritorna inoltre un puntatore all'adiacenza se il valore di ritorno é vero. Se fissiamo "0" come destinazione a livello1 si seleziona il più vicino IS a L2 (questo avviene quando siamo ad un IS-L1 e l'AreaAddress della destinazione é differente e quindi abbiamo bisogno di inoltrarlo in un'altra area). Se ci sono possibili multiple adiacenze, allora si sceglierà una a caso.
The Receive Process.
Performerà le seguenti funzioni:
1. se è un Data-NPDU ,indirizzata a questo sistema allora
decapsulerà la NPDU (rimuove l'header)
la passa alla ISO 8473
altrimenti
2. se é un Link State PDU , lo passa alle Updata Process.
3. se é una Sequence Numbers PDU, lo passa alla Update Process.
4. se é un IIH-PDU lo passa all'appropriata Subnetwork Dependent Function.
5. se contiene Data ma è destinata altrove allora lo passa al Forwarding Process.
6. altrimenti ignora la PDU.
Subnetwork Dependent Functions
Le SDF mascherano le caratteristiche dei differenti tipi di sottorete dalle SIRF (Subnetwork Independent Routing Function ). I due generici tipi di rete che queste riconoscono e supportano sono:
Broadcast Subnetworks : che supporta la capacità di indirizzare un gruppo di sistemi connessi alla rete con un singolo NPDU.
General Topology Subnetworks : che é il sistema generale di interconnessione point-to-point fra esattamente due sistemi e si divide in:
1) multipoint links : quando ci sono links tra più di due sistemi, dove un sistema é primario e gli altri secondari (questi ultimi per comunicare fra loro hanno bisogno del supporto del primario).
2) permanent point-to-point links : sono links connessi per tutto il tempo ( link dedicati ).
3) dynamically established data links (DED) : questi sono links su connessioni orientate, per esempio X.25 , ISDN ecc..., e possono inoltre essere usate in uno dei tre modi:
static point-to-point (Static) : il collegamento é stabilito su azione diretta del system management.
dynamic connection management (DCM) : il collegamento é stabilito alla ricezione del traffico e portato down alla terminazione di un timer ( cioè si instaura una particolare connessione solo quando deve essere utilizzata e per un periodo breve verrà utilizzata in modo dedicato ).
dynamically assigned (DA) : usa connessioni dinamiche in cui l'indirizzo a cui la chiamata é stata stabilita é determinata dinamicamente.
Ma vediamo ora le caratteristiche generali dell'SDF:
Con l'uso dello standard ISO 8473 Subnetwork Dependent Convergence Function, questo protocollo può trasmettere e ricevere le PDU sullo stesso tipo di sottorete (la descrizione di questo particolare protocollo non è nello scopo di questa RFC).
Con la coordinazione delle operazioni dell'ES-IS protocol (la comunicazione terminale tra IS ed ES) dell'ISO 9542 determina indirizzi di rete (nel caso di reti broadcast , determina l'SNPA) e determina l'entità di tutti i sistemi vicini. Queste informazione vengono messe nell'Adjacency database.
Controlla lo scambio delle IIH-PDUs.
Entriamo ora nella questione di come si fa a determinare e che cosa sono gli indirizzi che ci servono per la entry in un'altra rete di un altro dominio.
Noi sappiamo che tutte le informazioni di instradamento (LSP) di un dominio non lasciano il dominio. Cioé ogni sistema di un dominio avrà modo di conoscere solo e soltanto il suo dominio. Entrando nel dominio ci sono altre destinazioni da fare, in un'area tutte le routing information di L1 sono trasmesse a tutti gli IS di L1 e L2 di quell'area , mentre le informazioni di L2 saranno trasmesse solo a tutte le IS di L2 di tutto il dominio.
Ora ci possiamo chiedere dove sono le informazioni che ci permettono di collegare i domini. Queste inter-domain information sono immesse manualmente (e quindi sono dette static) dal system management, e rappresentano quelle Reachable Addresses che sono inclusi nelle L2-LSP generate da quell'IS settato per primo dal management. E quindi grazie alle L2-LSP le informazioni di inter-domain saranno disseminate a tutti gli L2-IS, e quest'ultimi ora oltre a fungere da inter-connessione fra aree può collegare due domini come router di frontiera.
Ora tutte le NPDU che sono destinate per delle NSAP incluse nell'addressPrefix del ReachableAddresses saranno inoltrate all'IS di frontiera. Alla sua ricezione questo IS le inoltrerà nell'appropriato circuito (point-to point) di frontiera. Nel caso invece di una rete multi-destination non é unica la SNPA-address e quindi é necessaria più informazione sugli indirizzi della rete per instradare bene la NPDU alla giusta SNPA (che può essere un IS o un ES dentro un altro dominio). Le S.N.P.A. (SubNetwork Point of Attachment possono essere derivate dalla destinazione NSAP della NPDU.
Ci sono vari metodi per ricavare questi indirizzi e come vedremo in seguito il più usato é estrarlo con degli algoritmi che data una NSAP ricavano una SNPA. Ci possono essere delle NSAP a cui non corrisponde nessuna SNPA e quindi viene scelta una SNPA di default. Lo specifico algoritmo di derivazione dell'indirizzo SNPA da quello NSAP sarà specificato nel Reachable Addresses.
Ora vediamo come si comportano le SDF nei diversi tipi di rete.In tutti i tipi di rete importanza fondamentale per comunicare tra gli IS o anche ES sono i pacchetti di Hello che saranno diversi e gestiti a seconda del tipo di rete verso cui sono inoltrati.
In reti Point-to-Point e in circuiti Static e DCM DED.
Per quanto riguarda i collegamenti tra ES ed IS il pacchetto di Hello sarà l'ESH-PDU , invece per collegamenti IS-IS ci sarà l'ISH ed IIH-PDU.
Nel primo tipo di collegamento quando una ESH-PDU é ricevuta da una IS allora l'indirizzo di origine, NSAP address, sarà messo nel database delle adiacenze; ogni volta che giunge una nuova ESH viene aggiunto il suo indirizzo , quando questo indirizzo é nuovo per il database la IS genererà un Adjacency State Change event; questo segnale è fondamentale per la corretta esecuzione dei processi dell'IS (ricordiamo che tutti gli IS funzionano in modo multitasking e quindi è necessario un controllo sulle memorie condivise ) cioè un qualsiasi utilizzo da parte del processo di decisione del database deve essere fatto posticipare all'avvenuto cambiamento della tabella in modo che la IS possa decidere avendo a disposizione una tabella di adiacenza aggiornata e non di una vecchia. Inoltre per far sì che sia sempre aggiornata ai cambiamenti, la IS aspetterà sempre un periodico Hello da parte dei suoi ES vicini , questo tempo, intervallo tra i vari ESH é settato man mano dagli stessi pacchetti ( e quindi dagli ES che li mandano ) grazie al campo Holding Time che ne stabiliscono la durata . Quando non si sarà ricevuta la ESH da un particolare ES prima che scada il suo timer allora la IS ricevente cancellerà il indirizzo dell'ES dal database , considerando questo come un cambiamento di topologia.
Vediamo ora come sono stabilite le adiacenze tra IS .
Quando un IS riceverà un ISH creerà un'adiacenza se non esiste e setterà i campi di State e di AdjacencyType. A seconda di come sono questi campi nelle adiacenze della IS ricevente e a seconda che la ID-portion della NET-field nella ISH PDU combaci o meno con la neighbourID della adiacenza, allora si cambieranno opportunamente dei campi e comunque si manderà un point-to-point IIH-PDU.
Quando si manda una IIH-PDU si setta il tipo del circuito (che può essere di L1, di L2 oppure di L1 ed L2 ), il LocalCircuitID (settato dall'IS quando il circuito è creato e che è un numero unico tra tutti i circuiti di quell'IS). Anche per quanto riguarda l'IIH-PDU ci sarà un campo HoldingTime che scandirà la trasmissione periodica delle IIH-PDU con le stesse modalità di quelle ESH. Inoltre il primo IIH-PDU mandato (che sarà quello di risposta alla ISH, non quello periodico dovuto alla terminazione del timer) sarà riempito in tutta la sua massima capienza così che la SNSDU (SubNetwork Service Data Unit) contenente la IIH avrà una lunghezza di almeno maxsize-1 byte, dove maxsize indica la massima grandezza che può avere una LSP ed un SNP. Questo si fà per assicurare che un adiacenza si formerà tra IS che sono capaci di scambiarsi qualsiasi tipo di PDU e di qualsiasi lunghezza ( fino a lunghezza maxsize byte ).
Quando un Point-to-Point IIH-PDU é ricevuto da un IS , l'AreaAddress dei due IS sarà confrontata per accertarsi della validità delle adiacenze.
Se le due IS hanno l'AreaAddress in comune , allora la adiacenza é valida per tutte le combinazioni di IS-type: cioé le adiacenze che porterà la IIH sarà valida quando le IS sono della stessa area , e sono tutte e due di L1, o sono tutte e due di L2, o sono una di L1 e l'altra di L2 con un circuito che ammette questa connessione ( cioé il flag manualL2OnlyMode é settato a falso ); quindi si escluderà il caso in cui due IS di livello differente saranno connessi con un circuito solo L2 ( e non si può avere alcuna possibile connessione con quel circuito a meno di modifica delle qualifiche delle IS ).
Se invece non avranno le AreaAddress in comune , la adiacenza é valida solo su IS di L2, poiché solo queste IS di L2 possono comunicare con altre IS di L2 di altre aree oltre che con quelle della propria area , poiché si devono scambiare le informazioni per gli scambi inter-area. Infatti alle IS di L2 non interessa sapere delle altre IS di L1 del suo vicino ( se non sono della stessa area ), mentre le informazioni delle IS di L1 della sua area già li tiene in memoria nella tabella di adiacenza.
Si deve notare che mentre la ESH é più semplice perché deve solo avvertire il suo IS che lei esiste (e questo é facile perché é una rete point-to-point), la ISH é più complessa perché una volta avvertito un altro IS che sta vicino ad esso , i due IS devono indicare se questa scoperta é una connessione fra IS di L1, fra IS di L2, oppure fra IS dei due livelli. Ecco perché c'é bisogno delle IIH-PDU , che si mandano fra di loro ; quando , per un motivo, non giunge più una IIH per più del tempo di Holding , se si vorrà risettare la IS si dovrà rimandare la ISH all'altro IS per far scoprire di quale connessione é ora (questo perché si é potuto anche cambiare di significato , di posizione topologica alla IS, cioé un cambiamento di livello, e quindi si deve portare a conscenza dell'altro IS che tipo di vicino ha ).
Vediamo adesso quello che succede con un:
Dynamically Assigned Circuits
Un circuito DA ha adiacenze multiple e può quindi stabilire Switched Virtual Cirìcuit a multiple SNPA. Le S.V.C. saranno stabilite secondo le procedure definite nell'ISO 8208 Subnetwork Dependent Convergence Functions dell'ISO 8473 . Questa sarà stabilita a seconda della rete: se é un Static circuit, un SVC sarà stabilito solamente su azione del system management; se é un DCM circuit, le procedure di stabilimento delle chiamate iniziano all'arrivo del traffico per il circuito.
Ritornando ora al discorso di come associare le NSAP alle SNPA , vediamo che in rete ISO 8208 tutte le NSAP accessibili hanno nelll'IDI il loro indirizzo SNPA, cioé la corretta SNPA può essere estratta dall'IDI. Poiché ci sono vari tipi di indirizzo (ISO DCC, X.121 adddresses) la tabella delle Reachable Addresses deve specificare per ogni prefisso il comportamento: riferimento diretto ad una SNPA (nell'esempio la X ); richiesta di estrazione della SNPA attraverso lo stesso prefisso IDI; ci sarà anche la * che si riferisce a tutti gli altri prefissi non menzionati.
Point-to-Point IS to IS Hello PDU

· VARIABLE LENGTH FIELDS:

Se CODE è uguale ad 1 allora il campo VALUE sarà il seguente:

Quando una NPDU deve essere forwardato su una dynamically assigned circuit, per una destinazione con indirizzo NSAP, la IS calcolerà l'indirizzo della sottorete, o la ricava esplicitamente dal circuit database oppure la estrae dall'IDP. Poi :
se l'indirizzo della sottorete calcolato é un ES , usa gli indirizzi che sono nella cache-entry.
se nella tabella sono specificate multiple SNPA allora scegliamo quella che ha già la adjacency in "up" , altrimenti si sceglie quello con il più vecchio time-stamp se non c'é nessuna corrispondenza nella tabella ( non c'é neanche la * ) allora si chiamerà il processo ISO 8473 Discard PDU Function.
Abbiamo visto prima come nei circuiti Static e DCM siano permesse le operazioni ISO 9542, Point-to-Point. Per DA circuit, non é possibile avere informazioni di configurazioni usando ISO 9542 , poiché questo richiederebbe chiamate a tutti i possibili SNPA addresses . La IS non spedirà né ISH né ESH , né tantomeno IIH-PDU su un DA circuit .Un circuito DA avrà e gestirà una lista di triple di < indirizzi prefissi raggiungibili , costo, SNPA address > e attraverso queste informazioni riuscirà a far conoscere la sua topologia agli IS ( ma nella nostra RFC non si specificano le sue modalità).
Vediamo cosa succede per una :
rete Broadcast
Tutti gli IS trasmettono LAN IIH-PDU , contenenti l'IS-ID del trasmettitore, l'HoldingTime (delle informazioni) , la priorità, e il manualAreaAddress, più tutti gli adiacenti IS dello stesso livello. A seconda di che livello é l'IS trasmettente, ci sono 2 tipi di pacchetto IIH-PDU, quelli di livello 1 trasmessi da IS di L1 e da IS di L2 con il manualL2OnlyMode settato a falso, e quelli di livello 2 trasmessi da qualsiasi tipo di IS di livello 2. Anche in queste IIH ci sarà bisogno di riempire al massimo il campo dati per poter poi affermare ( se il canale ha permesso questa capacità ) che le adiacenze avute saranno capaci di scambiarsi qualunque pacchetto LSP e SNP di qualsiasi grandezza.
Essendo la rete broadcast multi-destinazione, alla ricezione di un L1 LAN IIH-PDU, la IS dovrà paragonare la sua Area Address con quella contenuta nel pacchetto e cioé con quella dell'IS trasmettente, e a seconda se trovi o meno il match tra loro, accetterà le adiacenze, o rifiuterà il pacchetto ( perchè è di un'altra area ). Alla ricezione di un L2 LANIIH-PDU non c'è bisogno di confrontare le AreaAddress.
Un IS di livello 1 può ricevere pacchetti solo L1 LAN IIH-PDU trasmessi o da IS-L1 o da IS-L2 che hanno il manualL2OnlyMode a falso; così nel primo caso bisogna stare attenti che la nostra IS-L1 non riceva pacchetti da altre aree (ecco perchè si mette il filtro dell'AreaAddress in comune); nel secondo caso questi sono pacchetti L1 (quindi aventi informazioni di una specifica area ) spediti da L2 ad IS-L1 e anche qui non avrebbe senso spedire pacchetti da un IS-L2 ad un IS-L2 di un'altra area.
Per la ricezione invece da parte di IS di L2: esso può ricevere pacchetti solo L2 LAN IIH-PDU trasmessi o da IS-L2 che hanno manualL2 OnlyMode a falso o da quelli che lo hanno a vero; in entrambi i casi la comunicazione è sempre permessa e non si ha bisogno di limitazione poichè i vari L2 di tutto il dominio devono cominicare fra loro .
Quando si avrà che la IS che ha ricevuto la IIH-PDU di qualsiasi livello si tratti , avrà già la stessa adiacenza, allora esso aggiornerà l'HoldingTime e basta. Se invece la adiacenza ricevuta non sarà la stessa allora creerà una nuova adiacenza , se lo permetterà la capacità del database, se invece non c'è più spazio si sceglierà l'adiacenza con più bassa priorità e la sovrascriverà.
La trasmissione delle LAN IIH-PDU sia a L1 che a L2 sarà periodica e coinciderà con la terminazione di un timer ISISHelloTimer ( questo timer ha lo stesso significato dell'HoldingTimer del pacchetto IIH point-to-point ), il contenuto delle successive IIH-PDU differirà dal contenuto delle precedenti ; bisogna stare attenti a non far sincronizzare tutte le trasmissioni delle IIH-PDU che determinano un ingorgo sulla rete, e così si cerca di differenziare il settaggio del timer da IS a IS e anche da L1 a L2.
Come accennato nelle Subnetwork Independent Function , c'è bisogno di un LAN Designated IS. Ogni IS ha la possibilità di partecipare all'elezione dell'IS designato, ogni IS di L1 partecipa per quello di L1, quelli di L2 con il manualL2OnlyMode a vero eleggono solo quello di L2 , mentre quelli di L2 con il manualL2OnlyMode a falso possono partecipare alle elezioni di entrambi gli IS-Designated. L'IS-Designated performerà le azioni sull'LSP come detto per le S.I.F..
L'IS-Designated assumerà un funzione fondamentale quando c'è un cambiamento di topologia della LAN e quindi questo deve acquisire la End System Configuration in modo da generare al più presto la opportuna LSP.
Broadcast IS to IS Hello PDU

· VARIABLE LENGTH FIELDS:
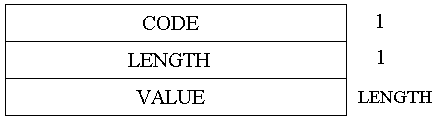
Se CODE è uguale ad 1 allora il campo VALUE sarà il seguente:

CODE è uguale a 6 allora il campo VALUE sarà il seguente:


clicca per tornare all'introduzione
oppure